



















VMM overhead
•Switchingload
•Interruptbottleneck
We can optimize the network I/O solution to solve both of the
issues above.
In Figure 5, we show the effect of using the new Intel® VMDq
hardware in our latest NICs along with the new VMware
NetQueue software in ESX 3.5. In this case, the network flows
destined for each of the VMs are switched in hardware on the
NIC itself and put into separate hardware queues. This greatly
simplifies the work that the virtualization software layer has
to do to forward packets to the destination VMs and delivers
improved CPU headroom for application VMs. Each of the queues
noted above is equipped with a dedicated interrupt signal that
can be directly routed to the destination VM for handling. This
allows us to spread the load of a 10 G pipe across the processor
cores running those VMs. In this way we can break through the
single-core interrupt processing bottleneck to deliver near line-
rate performance even at 10 GbE speeds.
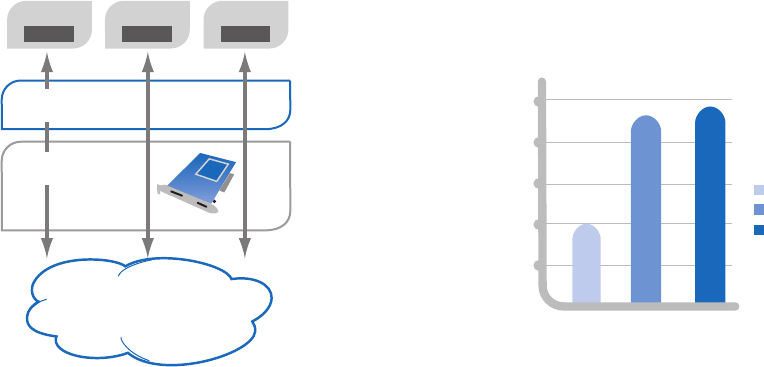
In Figure 6, we can see that the receive performance with
VMDq + NetQueue is 9.2 Gbps with standard 1518-byte packet
size and 9.5 Gbps with jumbo frames. This is more than double
the throughput without these new technologies enabled and
very close to maximum theoretical line rate.
VMDq and NetQueue
•Optimizeswitching
•Load-balanceinterrupts
VM
1
Virtual
VM
2
Virtual
VM
n
Virtual
NIC with
VMDq
VMware
with NetQueue
LAN
Figure 5. Network data flow for virtualization
with VMDq and NetQueue.
• 2x throughput
• Near Native 10 GbE
10.0
8.0
6.0
4.0
2.0
4.0
Throughput (GB)
9.2
9.5
With VMDq
Jumbo Frames
With VMDq
Without VMDq
Figure 6. Tests measure wire speed Receive (Rx) side performance
with VMDq on Intel® 82598 10 Gigabit Ethernet Controllers.
6
White Paper Consolidation of a Performance-Sensitive Application