



















A Detailed Look Inside the Intel
®
NetBurst
™
Micro-Architecture of the Intel Pentium
®
4 Processor
Page 10
Overview of the Intel
®
NetBurst
TM
Micro-architecture Pipeline
The pipeline of the Intel NetBurst micro-architecture contain three sections:
§ the in-order issue front end
§ the out-of-order superscalar execution core
§ the in-order retirement unit.
The front end supplies instructions in program order to
the out-of-order core. It fetches and decodes IA-32
instructions. The decoded IA-32 instructions are
translated into micro-operations (µops). The front end’s
primary job is to feed a continuous stream of µops to
the execution core in original program order.
The core can then issue multiple µops per cycle, and
aggressively reorder µops so that those µops, whose
inputs are ready and have execution resources available,
can execute as soon as possible. The retirement section
ensures that the results of execution of the µops are
processed according to original program order and that
the proper architectural states are updated.
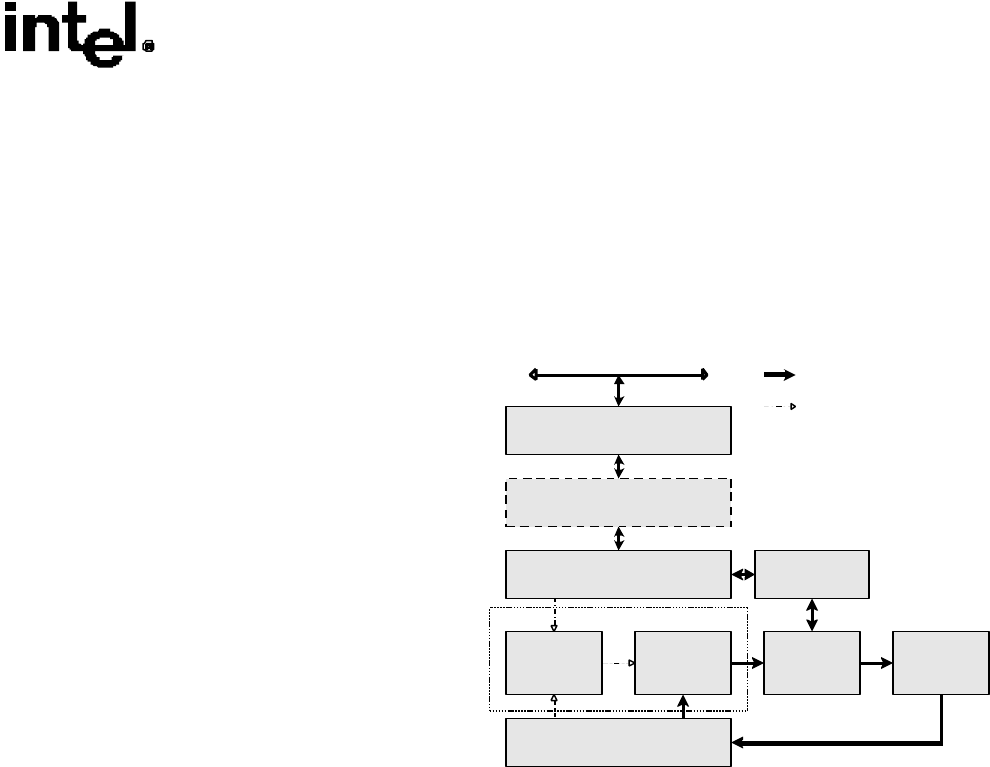
Figure 3 illustrates a block diagram view of the major
functional blocks associated with the Intel NetBurst
micro-architecture pipeline. The paragraphs that follow
Figure 3 provide an overview of each of the three
sections in the pipeline.
The Front End
The front end of the Intel NetBurst micro-architecture consists of two parts:
§ fetch/decode unit
§ execution trace cache.
The front end performs several basic functions:
§ prefetches IA-32 instructions that are likely to be executed
§ fetches instructions that have not already been prefetched
§ decodes instructions into µops
§ generates microcode for complex instructions and special-purpose code
§ delivers decoded instructions from the execution trace cache
§ predicts branches using highly advanced algorithm.
The front end of the Intel NetBurst micro-architecture is designed to address some of the common problems in high-
speed, pipelined microprocessors. Two of these problems contribute to major sources of delays:
§ the time to decode instructions fetched from the target
§ wasted decode bandwidth due to branches or branch target in the middle of cache lines.
The execution trace cache addresses both of these problems by storing decoded IA-32 instructions. Instructions are
fetched and decoded by a translation engine. The translation engine builds the decoded instruction into sequences of
Fetch/Decode
Trace Cache
Microcode ROM
Execution
Out-Of-Order Core
Retirement
1st Level Cache
4-way
2nd Level Cache
8-Way
BTBs/Branch Prediction
Bus Unit
System Bus
Frequently used paths
Less frequently used paths
Front End
3rd Level Cache
Optional, Server Product Only
Branch History Update
Figure 3 The Intel
®
NetBurst
TM
Micro-architecture