



















16
Th
e
Ult
ra
SPARC
T
2
P
rocessor w
ith
C
oo
lTh
rea
d
s
T
ec
h
no
l
ogy Sun Microsystems, Inc.
An eight-stage integer pipeline and a 12-stage floating-point pipeline are provided by
each UltraSPARC processor core (Figure 7). A new “pick” pipeline stage has been added
to choose two threads (out of the eight possible per core) to execute each cycle.
Figure 7. UltraSPARC T2 per-core integer and floating-point pipelines
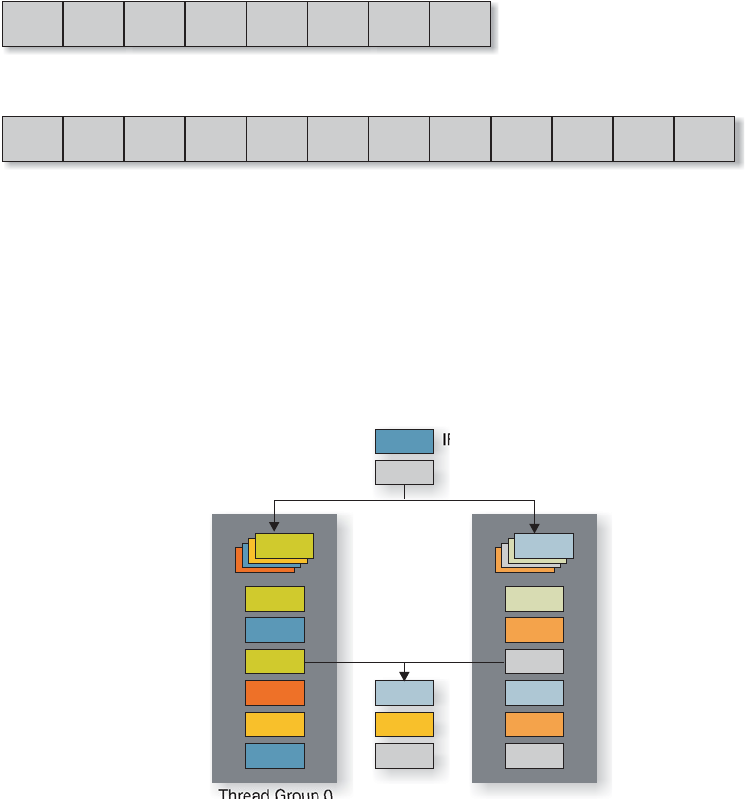
To illustrate how the dual pipelines function, Figure 8 depicts the integer pipeline with
the load store unit (LSU). The instruction cache is shared by all eight threads within the
core. A least-recently-fetched algorithm is used to select the next thread to fetch. Each
thread is written into a thread-specific instruction buffer (IB) and each of the eight
threads is statically assigned to one of two thread groups within the core.
Figure 8. Threads are interleaved between pipeline stages with very few restrictions (integer pipeline
shown, letters depict pipeline stages, numbers depict different scheduled threads)
The “pick” stage chooses one thread each cycle within each thread group. Picking
within each thread group is independent of the other, and a least-recently-picked
algorithm is used to select the next thread to execute. The decode state resolves
resource conflicts that are not handled during the pick stage. As shown in the
illustration, threads are interleaved between pipeline stages with very few restrictions.
Any thread can be at the fetch or cache stage, before being split into either of the two
thread groups. Load/store and floating point units are shared between all eight
threads. Only one thread from either thread group can be scheduled on such a shared
unit.
Eight-Stage Integer Pipeline
Twelve-Stage Floating-Point Pipeline
Fetch
Cache
Pick Decode Execute
Fx1 Fx2
Fx3
Fx4
Fx5
Fx6
FW
Fetch
Cache
Pick Decode Execute Mem
Bypass
W
LSU
Thread Group 0
IFU
IB0-3
IB0-3
IB0-3
IB0-3
P0
W2
B1
M3
E0
D2
IB0-3
IB0-3
IB0-3
IB4-7
P5
W6
B7
M4
E6
D7
Thread Group 1
W6
B1
M4
C6
F2