



















96 Storage Management with DB2 for OS/390
traditional disaster recovery, is that each software subsystem (CICS, IMS, DB2,
VSAM, and others) has its own recovery technique. Because an application is
typically made up of multiple software subsystems, it is impossible to get a
time-consistent backup across all subsystems unless the application is stopped,
which impacts availability. Please note that backups are still required in a remote
copy environment.
Duplication can be done on the secondary server either
synchronously or
asynchronously with the primary server update. The IBM 3990 open extended
architecture defines peer-to-peer remote copy (
PPRC) for synchronous
environments and
extended remote copy (XRC) for asynchronous environments.
To provide an operational disaster recovery solution, data consistency is
mandatory for secondary remote copy volumes should any event occur to the
primary, the secondary, or to links between primary and secondary. Continuous
availability of the primary site is also mandatory when secondary site outage
occurs. For consistency reasons, we recommend choosing only one remote copy
technique, synchronous or asynchronous, for a given environment.
9.5.4.1 PPRC
PPRC allows two disk storage servers to directly communicate with each other
through ESCON links. The storage servers can be sited up to 43 km apart. The
remote copies are established between two disk volumes. Once the pairs are
synchronized, the storage servers maintain the copies by applying all updates to
both volumes. Updates must be received at both storage servers before the I/O is
posted as complete to the application making PPRC operation
synchronous.
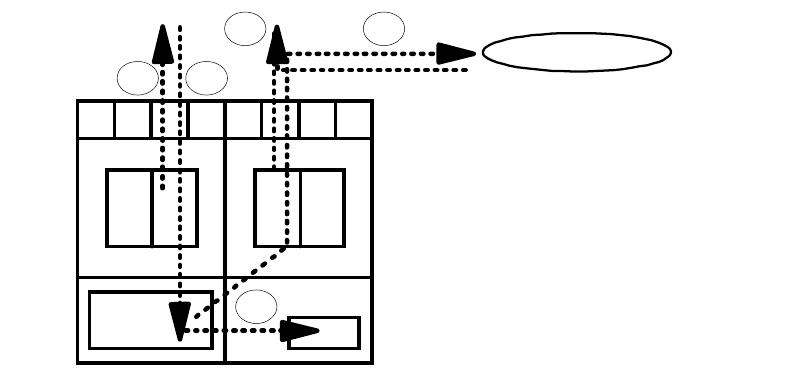
Figure 28 on page 96 shows the PPRC data flow (where SP stands for Storage
Path).
Figure 28. Profile of a PPRC Write
PPRC operations are entirely at the disk volume level. Write sequence
consistency
is preserved by the updates being propagated to the second site in
real time. Databases that are spread across multiple volumes may be
unrecoverable if a
rolling disaster causes the secondary volumes to be at an
inconsistent level of updates. A rolling disaster is one where various components
fail in sequence. For example, if a data volume failed to update its secondary, yet
the corresponding log update was copied to the secondary, this would result in a
secondary copy of the data that is inconsistent with the primary copy. The
to/from remote controller
CACHE NVS
Notes:
- Steps 3 and 4 are disconnect time
SP is busy
- Steps 1 through 4 are service time
UCB is busy
1. Write to local cache and NVS
2. Channel End - channel is free
3. Write to remote cache and NVS
4. Device End upon acknowledgment
1
1
2
4
3