












62
Chapter 5
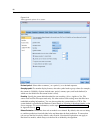
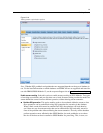
reduce network traffic and speed stream operations. Note that the Generate SQL check box
must be selected for SQL optimization to have any effect.
Optimize syntax execution.
This method of stream rewriting increases the efficiency of
operations that incorporate more than one node containing IBM® SPSS® Statistics syntax.
Optimization is achieved by combining the syntax commands into a single operation, instead
of running each as a separate operation.
Optimize other execution.
This method of stream rewriting increases the efficiency of
operations that cannot be delegated to the database. Optimization is achieved by reducing the
amount of data in the stream as early as possible. While maintaining data integrity, the stream
is rewritten to push oper ations closer to the data source, thus reduc ing data downstream for
costly oper
ations, such as joins.
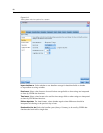
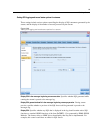
Enable parallel processing.
When running on a computer with multiple processors, this option
allows the system to balance th e load acros s those proces sors, which may result in faster
performanc
e. Use of multiple nodes or use of the following individual nodes m ay benefit from
parallel processing: C5.0, Merge (by key), Sort, Bin (rank and tile methods), and Aggregate
(using one or mor e key fields).
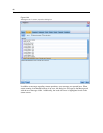
Generate S
QL.
Select this option to enable SQL generation, allowing stream operations to be pushed
back to the database by using S QL code to generate execution processes, which may improv e
performance. To further improve performance, Optimize SQL generation can also be selected to
maximiz e t
he number of operations p ushed back to the database. When operations f or a node have
been pushed back to the d atabase, the node will be highlighted in purple when the stream is run.
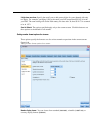
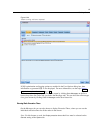
Database caching.
For streams that generate SQL to be executed in the database, data can be
cached mi
dstream to a temporary table in the database rather than to the file system. When
combined with SQL optimization, this may result in significant gains in per f ormance. F or
example, the output from a stream that merges multiple tables to crea te a data mining view
may be cached and reused as needed. With database caching enabled, simply right-click any
nonterminal node to cache data at that point, and the cache is a utomatically cr eated directly in
the database the next time the stream is run. This allows SQL to be generated for downs tream
nodes, f
urther improving performanc e. Alternatively, this option can be disabled if needed,
such as when policies or permissions preclude data being written to the data base. If database
caching or SQL optimization is not enabled, the cache will be written to the file system
instead. For mor e informatio n, see the topic Caching Options for Nodes on p. 50.
Use re
laxed conversion.
This option enables the conversion of data from either strings to
numbers, or numbe r s to strings, if stored in a suitable format. For example, if the data is
kept in the database as a string, but actually contains a meaningful number, the data can be
converted for use when the pushback occurs.
Note: Due to minor differences in SQL implementation, streams run in a database may return
slightly different results from those returned when run in SPSS Mo deler. For similar reasons, these
differences may also vary depending on the database vendor.
Save As Default.
The options specified apply only to the current stream. Click this button to set
these options as the default for all streams.