



















98 Cache and Memory Optimizations Chapter 5
25112 Rev. 3.06 September 2005
Software Optimization Guide for AMD64 Processors
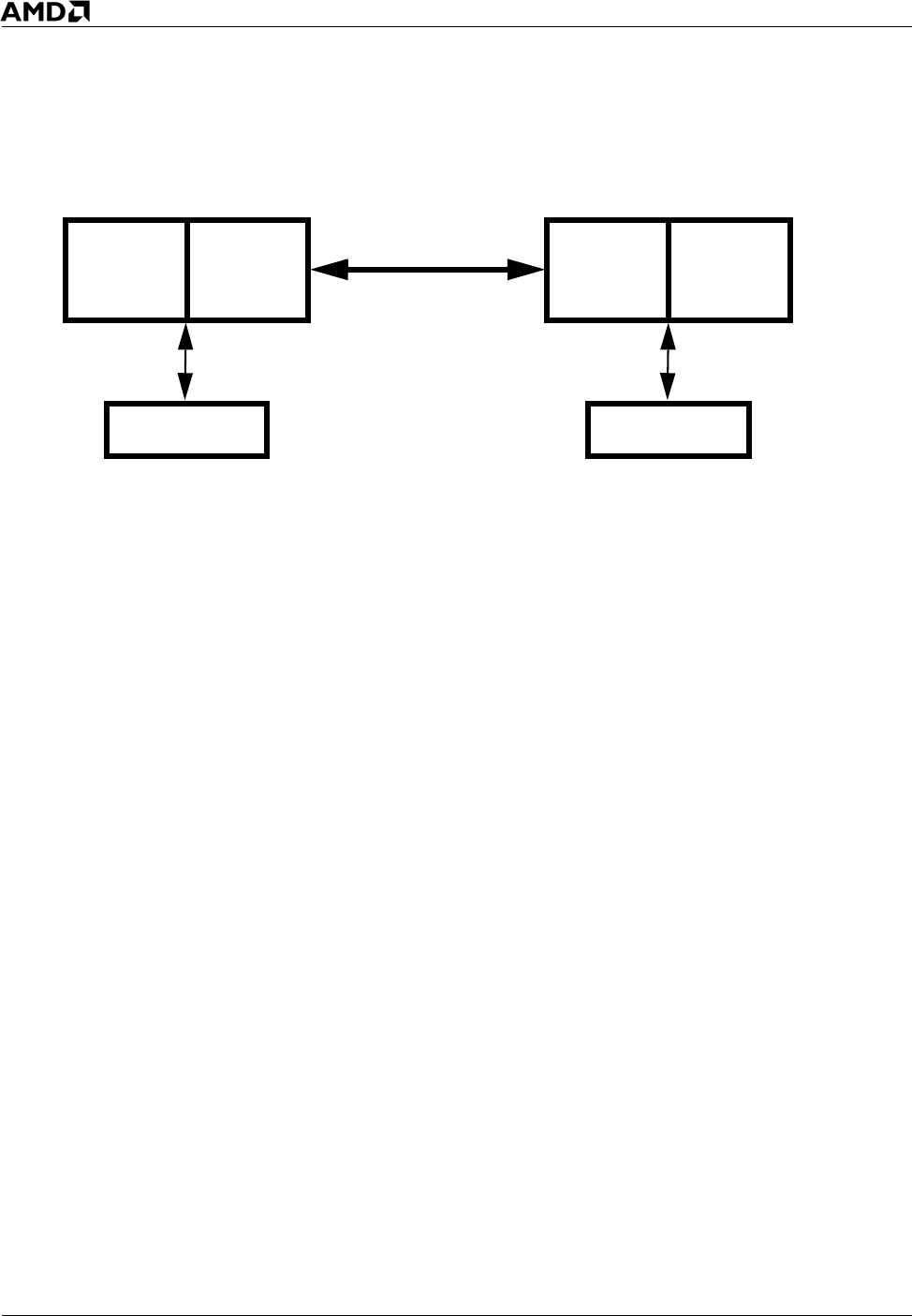
Figure 3. Dual-Core AMD Opteron™ Processor Configuration
OS Implications
An operating system running on an AMD Opteron platform will coordinate and manage the memory
configuration so that an application does not have to be aware of this memory configuration. Thanks
to the OS, the platform will simply appear to have one contiguous block of memory regardless of how
many processors are in the platform.
Because of the difference in latencies in ccNUMA systems, the OS must make determinations that
enable the best performance. It would be undesirable, for example, to spawn a thread on a processor
while allocating the memory space for that thread on a different processor. For such reasons, it is
important to be aware of the capabilities of the OS being used. Microsoft's Windows Server 2003
products are ccNUMA aware. The SUSE distribution of 64-bit Linux also has a ccNUMA aware
kernel for AMD64 processors.
Windows applications that spawn several threads, where each thread operates on largely independent
data, might benefit from distributing those threads across several processors and allocating memory
locally for each thread. This can be accomplished by using the SetThreadAffinityMask( ) function
and by allocating memory blocks using VirtualAlloc( ) from within the thread that will be heavily
accessing that memory block. Memory is not actually committed until it is accessed and then it is
committed to the node that accesses it. For this reason, it is a good idea to initialize that memory
block using memset() or other code which causes all the pages in the block to be accessed if there is a
chance another node could access it first. See the Microsoft documentation on MSDN for more
details (search for SetThreadAffinityMask( )).
AMD Opteron
TM
Dual-Core Processor 1
AMD Opteron
TM
Dual-Core Processor 0
HyperTransport
TM
Core 0 Core 1 Core 2 Core 3
Memory Memory