



















352 AGP Considerations Appendix D
25112 Rev. 3.06 September 2005
Software Optimization Guide for AMD64 Processors
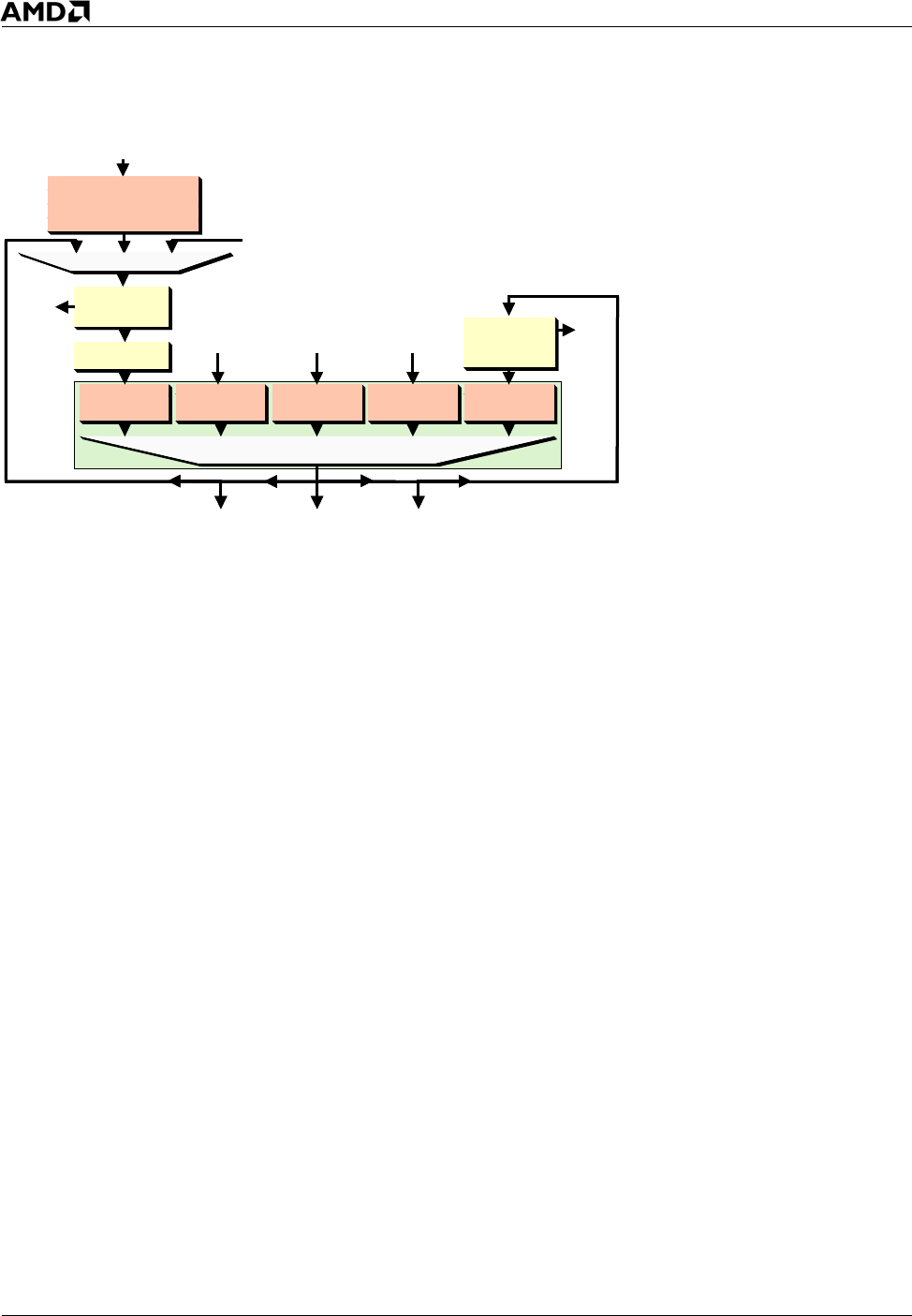
Figure 12. Northbridge Command Flow
D.5 Memory Optimizations for Graphics-Engine
Programming Using the DMA Model
Historically (that is, with AGP 1.0 and AGP 2.0), AGP memory used for command DMA buffers was
accessed by the processor through the AGP aperture space (this feature is referred to as host
translation). This address space was mapped as write-combining due to the fact that the processor’s
caches were not snooped by an AGP master (that is, coherency was not enforced for AGP memory).
Write-combining offered the best bandwidth in this situation because write-combining buffers could
be sent to system memory as full write-combining buffers. However, system memory still needed to
be written, which used memory bandwidth.
On current systems however, coherency between an AGP master (making accesses through the AGP
aperture) and the processor caches is maintained due to the HyperTransport protocol and the MOESI
(modified, owner, exclusive, shared, invalid) caching policy. Coherency support between an AGP
master and the processor caches is enabled through a bit in the GART entry (Gart_entry.coh). The
AGP miniport driver sets this bit as it maps entries in the GART. The video graphics miniport driver
can verify this feature in the AGP 3.0-compliant register (AGPSTAT.ita_entry.coh), which is found in
the AGP bridge device.
Note: Coherency support is implemented by hardware in AMD Athlon 64 and AMD Opteron
processors, and is not specific to the AGP tunnel device, even though the support is indicated
in the tunnel’s AGP 3.0-compliant register (AGPSTAT.ita_entry.coh).
Therefore, a key optimization for the DMA model on AMD Athlon 64 and AMD Opteron processors
is that the AGP master may read the data from the processor caches faster than reading data from the
DDR memory, since the processor caches operate at higher clock frequencies. As processor clock
Address MAP
& GART
System Request
Queue
24-entry
CPU 0
All buffers are 64-bit
command/address
Router
10-entry Buffer
Router
16-entry Buffer
Router
16-entry Buffer
Router
16-entry Buffer
Router
12-entry Buffer
Memory
Command
Queue
20-entry
CPU 1
HyperTransport 0
Input
HyperTransport 1
Input
HyperTransport 2
Input
Victim Buffer (8-entry)
Write Buffer (4-entry)
Instruction MAB (2-entry)
Data MAB (8-entry)
to
DCT
Hypertransport 0
Out
p
ut
HyperTransport 1
Out
p
ut
HyperTransport 2
Out
p
ut
to
CPU
XBAR
Address MAP
& GART
System Request
Queue
24-entry
CPU 0
All buffers are 64-bit
command/address
Router
10-entry Buffer
Router
10-entry Buffer
Router
16-entry Buffer
Router
16-entry Buffer
Router
16-entry Buffer
Router
16-entry Buffer
Router
16-entry Buffer
Router
16-entry Buffer
Router
12-entry Buffer
Router
12-entry Buffer
Memory
Command
Queue
20-entry
CPU 1
HyperTransport 0
Input
HyperTransport 1
Input
HyperTransport 2
Input
Victim Buffer (8-entry)
Write Buffer (4-entry)
Instruction MAB (2-entry)
Data MAB (8-entry)
to
DCT
Hypertransport 0
Out
p
ut
HyperTransport 1
Out
p
ut
HyperTransport 2
Out
p
ut
to
CPU
XBAR