



















330 Instruction Latencies Appendix C
25112 Rev. 3.06 September 2005
Software Optimization Guide for AMD64 Processors
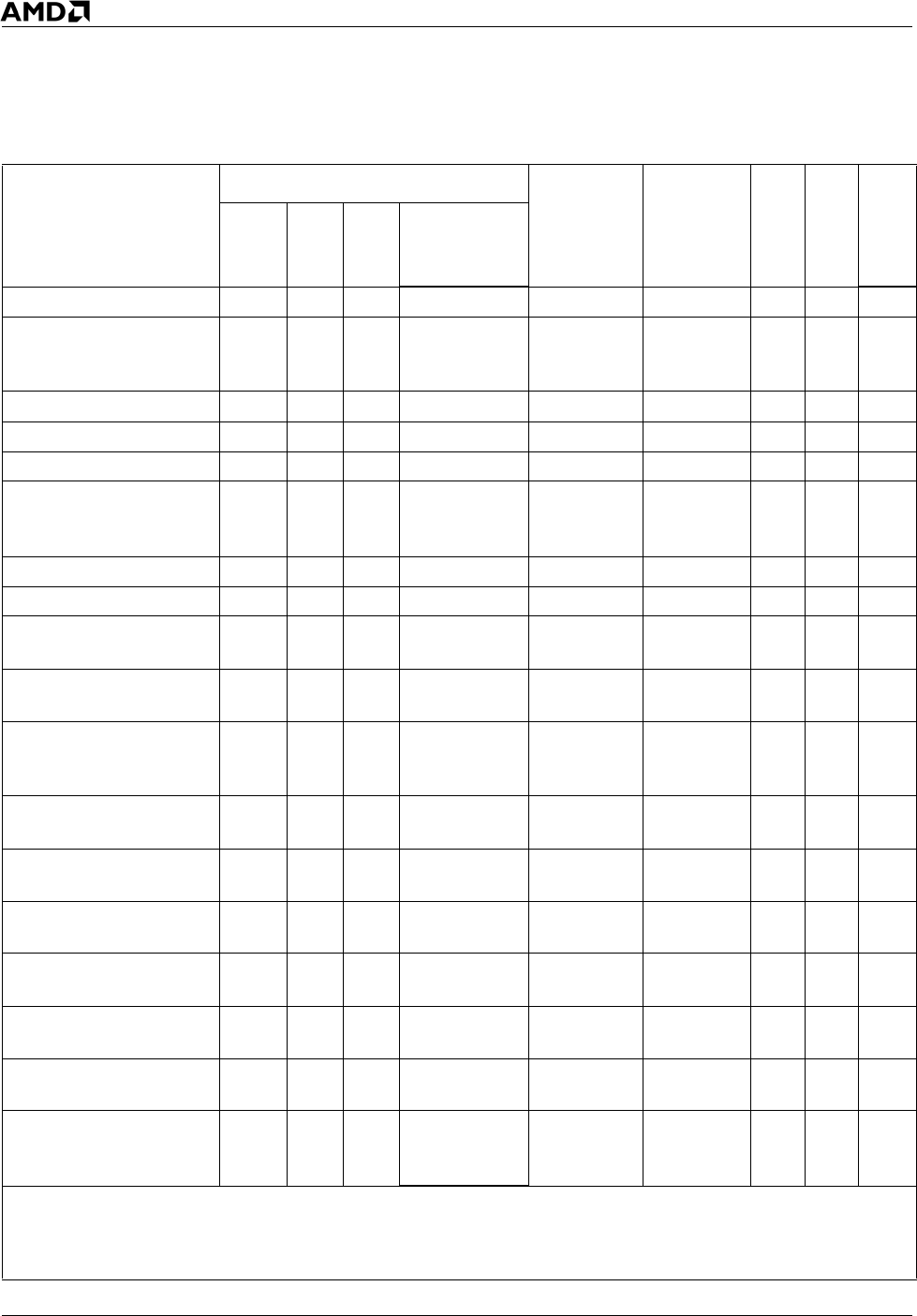
MOVD xmmreg, reg32 66h 0Fh 6Eh 11-xxx-xxx VectorPath ~ 9
MOVD xmmreg, mem32 66h 0Fh 6Eh mm-xxx-xxx Double FADD/
FMUL/
FSTORE
4
MOVD reg32, xmmreg 66h 0Fh 7Eh 11-xxx-xxx Double FSTORE 4
MOVD mem32, xmmreg 66h 0Fh 7Eh mm-xxx-xxx DirectPath FSTORE 2
MOVD xmmreg, reg64 66h 0Fh 6Eh 11-xxx-xxx VectorPath ~ 9
MOVD xmmreg, mem64 66h 0Fh 6Eh mm-xxx-xxx Double FADD/
FMUL/
FSTORE
4
MOVD reg64, xmmreg 66h 0Fh 7Eh 11-xxx-xxx Double FSTORE 4
MOVD mem64, xmmreg 66h 0Fh 7Eh mm-xxx-xxx DirectPath FSTORE 2
MOVDQ2Q mmreg,
xmmreg
F2h 0Fh D6h 11-xxx-xxx DirectPath FADD/
FMUL
2
MOVDQA xmmreg1,
xmmreg2
66h 0Fh 6Fh 11-xxx-xxx Double FADD/
FMUL
2
MOVDQA xmmreg,
mem128
66h 0Fh 6Fh mm-xxx-xxx Double FADD/
FMUL/
FSTORE
2
MOVDQA xmmreg1,
xmmreg2
66h 0Fh 7Fh 11-xxx-xxx Double FADD/
FMUL
2
MOVDQA mem128,
xmmreg
66h 0Fh 7Fh mm-xxx-xxx Double FSTORE 3
MOVDQU xmmreg1,
xmmreg2
F3h 0Fh 6Fh 11-xxx-xxx Double FADD/
FMUL
2
MOVDQU xmmreg,
mem128
F3h 0Fh 6Fh mm-xxx-xxx VectorPath ~ 7
MOVDQU xmmreg1,
xmmreg2
F3h 0Fh 7Fh 11-xxx-xxx Double FADD/
FMUL
2
MOVDQU mem128,
xmmreg
F3h 0Fh 7Fh mm-xxx-xxx VectorPath FSTORE 4
MOVHPD xmmreg,
mem64
66h 0Fh 16h mm-xxx-xxx DirectPath FADD/
FMUL/
FSTORE
2
Table 19. SSE2 Instructions (Continued)
Syntax
Encoding
Decode
type
FPU
pipe(s)
Latency
Throughput
Note
Prefix
byte
First
byte
2nd
byte
ModRM byte
Notes:
1. The low half of the result is available one cycle earlier than listed.
2. This is the execution latency for the instruction. The time to complete the external write depends on the memory
speed and the hardware implementation.