



















298 Instruction Latencies Appendix C
25112 Rev. 3.06 September 2005
Software Optimization Guide for AMD64 Processors
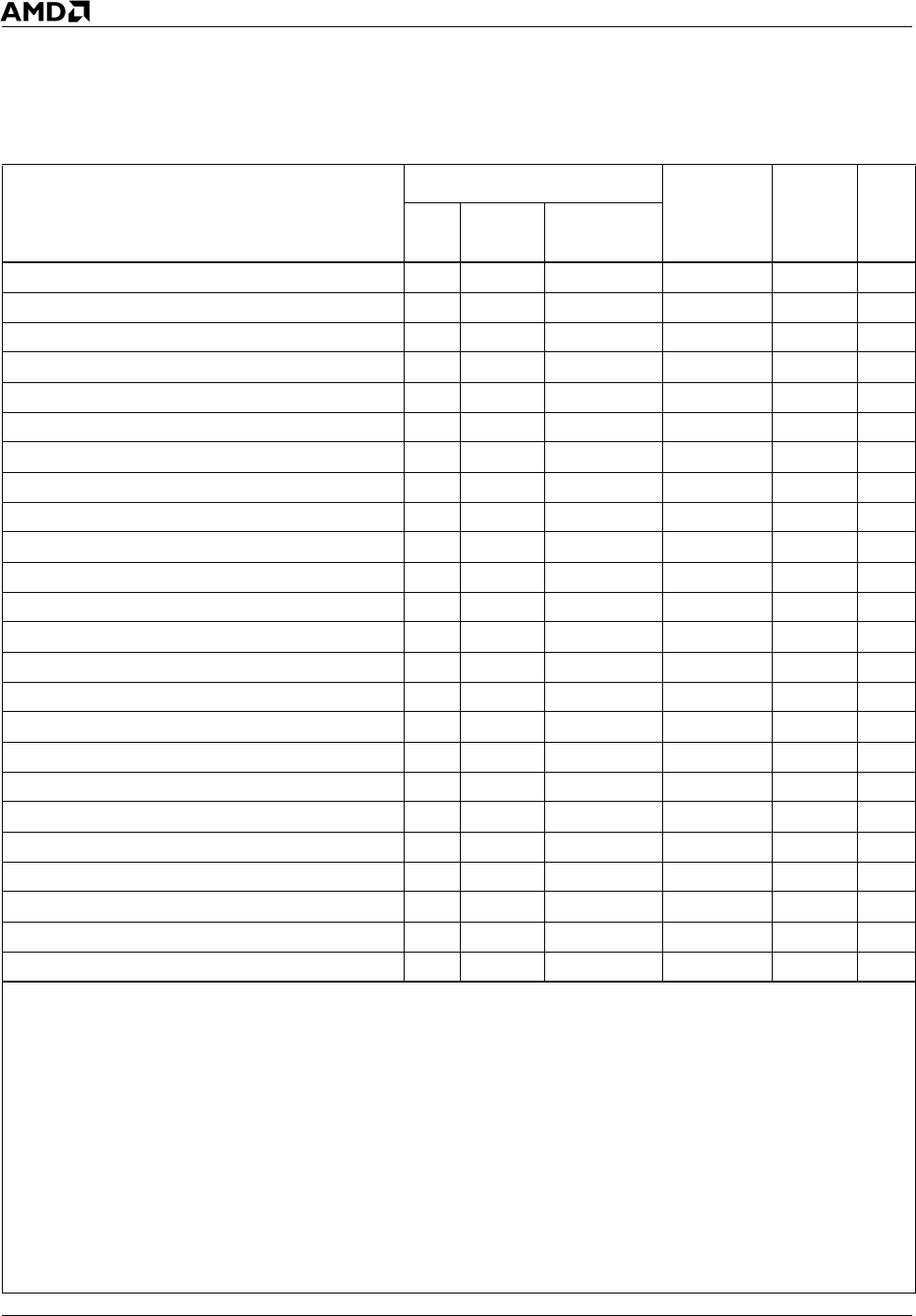
SHL/SAL mreg8, CL D2h 11-100-xxx DirectPath 1 3
SHL/SAL mem8, CL D2h mm-100-xxx DirectPath 4 3
SHL/SAL mreg16/32/64, CL D3h 11-100-xxx DirectPath 1 3
SHL/SAL mem16/32/64, CL D3h mm-100-xxx DirectPath 4 3
SHLD mreg16/32/64, reg16/32/64, imm8 0Fh A4h 11-xxx-xxx VectorPath 4 3
SHLD mem16/32/64, reg16/32/64, imm8 0Fh A4h mm-xxx-xxx VectorPath 6 3
SHLD mreg16/32/64, reg16/32/64, CL 0Fh A5h 11-xxx-xxx VectorPath 4 3
SHLD mem16/32/64, reg16/32/64, CL 0Fh A5h mm-xxx-xxx VectorPath 6 3
SHR mreg8, imm8 C0h 11-101-xxx DirectPath 1 3
SHR mem8, imm8 C0h mm-101-xxx DirectPath 4 3
SHR mreg16/32/64, imm8 C1h 11-101-xxx DirectPath 1 3
SHR mem16/32/64, imm8 C1h mm-101-xxx DirectPath 4 3
SHR mreg8, 1 D0h 11-101-xxx DirectPath 1
SHR mem8, 1 D0h mm-101-xxx DirectPath 4
SHR mreg16/32/64, 1 D1h 11-101-xxx DirectPath 1
SHR mem16/32/64, 1 D1h mm-101-xxx DirectPath 4
SHR mreg8, CL D2h 11-101-xxx DirectPath 1 3
SHR mem8, CL D2h mm-101-xxx DirectPath 4 3
SHR mreg16/32/64, CL D3h 11-101-xxx DirectPath 1 3
SHR mem16/32/64, CL D3h mm-101-xxx DirectPath 4 3
SHRD mreg16/32/64, reg16/32/64, imm8 0Fh ACh 11-xxx-xxx VectorPath 4 3
SHRD mem16/32/64, reg16/32/64, imm8 0Fh ACh mm-xxx-xxx VectorPath 6 3
SHRD mreg16/32/64, reg16/32/64, CL 0Fh ADh 11-xxx-xxx VectorPath 4 3
SHRD mem16/32/64, reg16/32/64, CL 0Fh ADh mm-xxx-xxx VectorPath 6 3
Table 13. Integer Instructions (Continued)
Syntax
Encoding
Decode
type
Latency Note
First
byte
Second
byte
ModRM
byte
Notes:
1. Static timing assumes a predicted branch.
2. Store operation also updates ESP—the new register value is available one clock earlier than the specified
latency.
3. The clock count, regardless of the number of shifts or rotates, as determined by CL or imm8.
4. LEA instructions have a latency of 1 when there are two source operands (as in the case of the base + index
form LEA EAX, [EDX+EDI]). Forms with a scale or more than two source operands will have a latency of 2 (LEA
EAX, [EBX+EBX*8]).
5. These instructions have an effective latency as shown. They map to internal NOPs that can be issued at a rate of
three per cycle but do not occupy execution resources.
6. The latency of repeated string instructions can be found in “Latency of Repeated String Instructions” on
page 167.
7. The first latency value is for 32-bit mode. The second is for 64-bit mode.
8. This opcode is used as a REX prefix in 64-bit mode.