



















Appendix A Microarchitecture for AMD Athlon™ 64 and AMD Opteron™ Processors 253
Software Optimization Guide for AMD64 Processors
25112 Rev. 3.06 September 2005
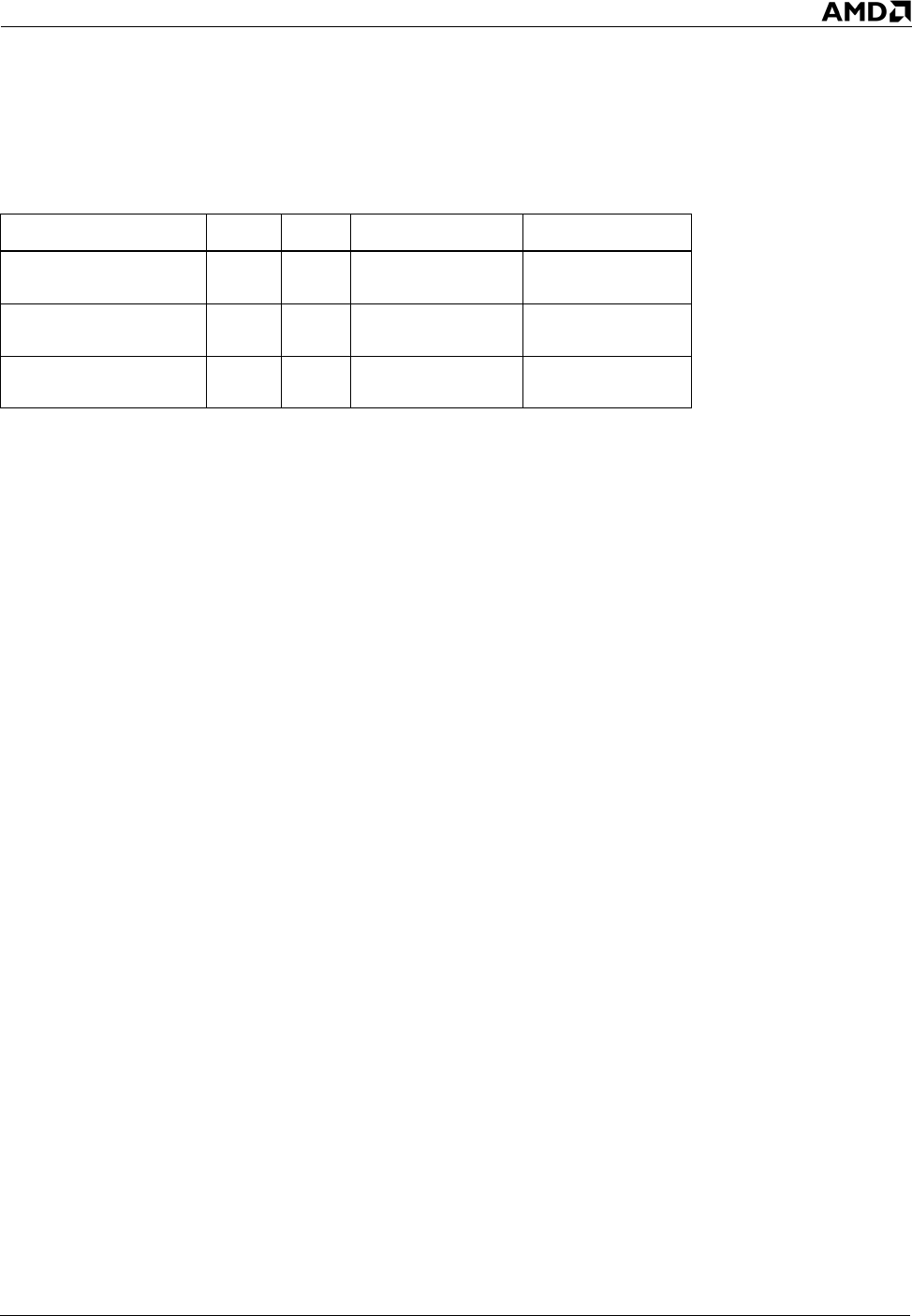
Table 7 provides specifications on the L1 instruction cache for various AMD processors.
Predecoding begins as the L1 instruction cache is filled. Predecode information is generated and
stored alongside the instruction cache. This information is used to help efficiently identify the
boundaries between variable length AMD64 instructions.
A.6 Branch-Prediction Table
The AMD Athlon 64 and AMD Opteron processors assume that a branch is not taken until it is taken
once. Then it is assumed that the branch is taken, until it is not taken. Thereafter, the branch
prediction table is used.
The fetch logic accesses the branch prediction table in parallel with the L1 instruction cache. The
information stored in the branch prediction table is used to predict the direction of branch
instructions. When instruction cache lines are evicted to the L2 cache, branch selectors and predecode
information are also stored in the L2 cache.
The AMD Athlon 64 and AMD Opteron processors employ combinations of a branch target address
buffer (BTB), a global history bimodal counter (GHBC) table, and a return address stack (RAS) to
predict and accelerate branches. Predicted-taken branches incur only a single-cycle delay to redirect
the instruction fetcher to the target instruction. In the event of a misprediction, the minimum penalty
is 10 cycles.
The BTB is a 2048-entry table that caches in each entry the predicted target address of a branch. The
16384-entry GHBC table contains 2-bit saturating counters used to predict whether a conditional
branch is taken. The GHBC table is indexed using the outcome (taken or not taken) of the last eight
conditional branches and 4 bits of the branch address. The GHBC table allows the processors to
predict branch patterns of up to eight branches.
In addition, the processors implement a 12-entry return address stack to predict return addresses from
a near or far call. As calls are fetched, the next rIP is pushed onto the return stack. Subsequent returns
pop a predicted return address off the top of the stack.
Table 7. L1 Instruction Cache Specifications by Processor
Processor name Family Model Associativity Size (Kbytes)
AMD Athlon™ XP
processor
6 6 2 ways 64
AMD Athlon™ 64
processor
15 All 2 ways 64
AMD Opteron™
processor
15 All 2 ways 64