



















Appendix C Instruction Latencies 305
Software Optimization Guide for AMD64 Processors
25112 Rev. 3.06 September 2005
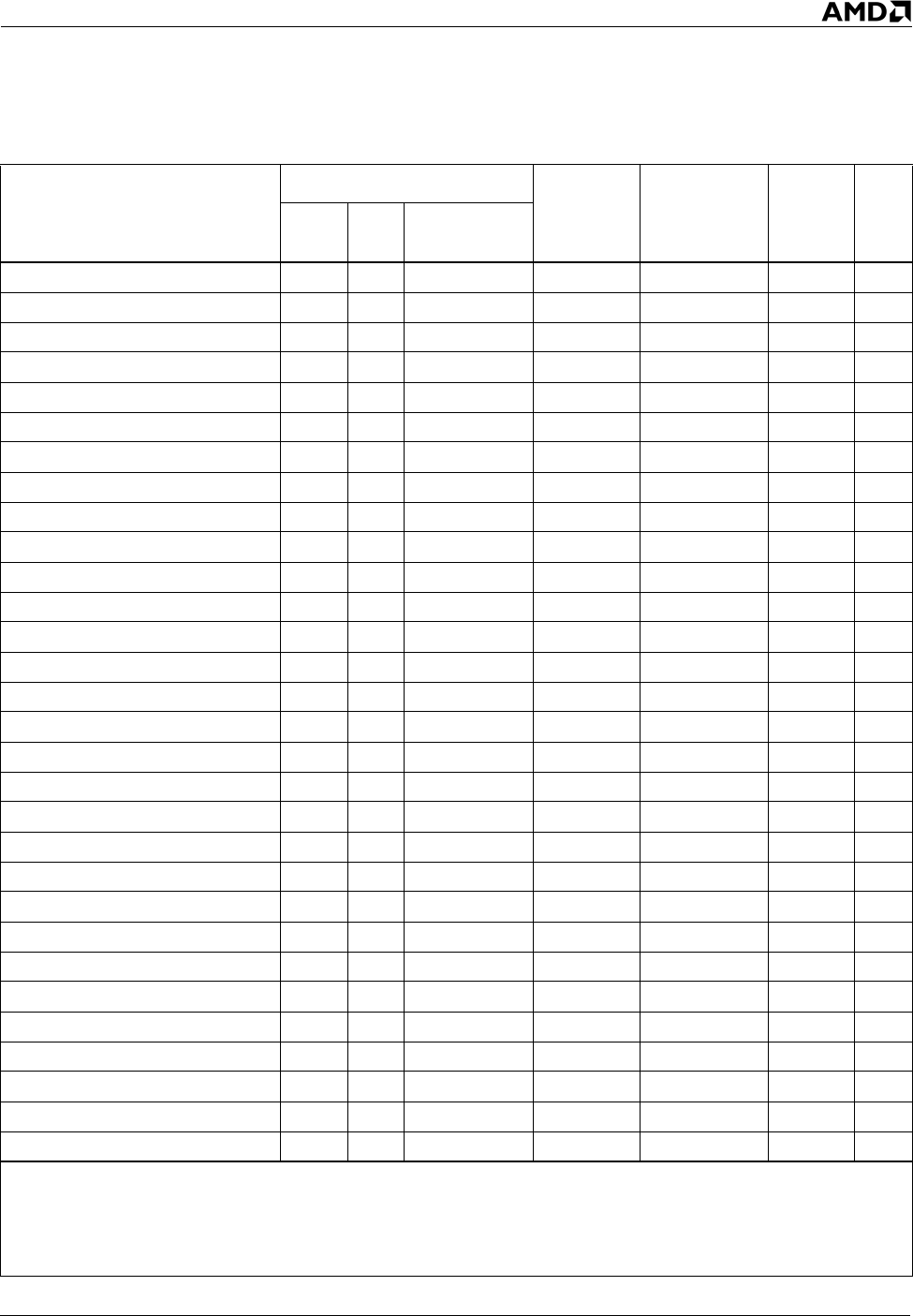
POR mmreg1, mmreg2 0Fh EBh 11-xxx-xxx DirectPath FADD/FMUL 2
POR mmreg, mem64 0Fh EBh mm-xxx-xxx DirectPath FADD/FMUL 4
PSLLD mmreg1, mmreg2 0Fh F2h 11-xxx-xxx DirectPath FADD/FMUL 2
PSLLD mmreg, mem64 0Fh F2h mm-xxx-xxx DirectPath FADD/FMUL 4
PSLLD mmreg, imm8 0Fh 72h 11-110-xxx DirectPath FADD/FMUL 2
PSLLQ mmreg1, mmreg2 0Fh F3h 11-xxx-xxx DirectPath FADD/FMUL 2
PSLLQ mmreg, mem64 0Fh F3h mm-xxx-xxx DirectPath FADD/FMUL 4
PSLLQ mmreg, imm8 0Fh 73h 11-110-xxx DirectPath FADD/FMUL 2
PSLLW mmreg1, mmreg2 0Fh F1h 11-xxx-xxx DirectPath FADD/FMUL 2
PSLLW mmreg, mem64 0Fh F1h mm-xxx-xxx DirectPath FADD/FMUL 4
PSLLW mmreg, imm8 0Fh 71h 11-110-xxx DirectPath FADD/FMUL 2
PSRAD mmreg1, mmreg2 0Fh E2h 11-xxx-xxx DirectPath FADD/FMUL 2
PSRAD mmreg, mem64 0Fh E2h mm-xxx-xxx DirectPath FADD/FMUL 4
PSRAD mmreg, imm8 0Fh 72h 11-100-xxx DirectPath FADD/FMUL 2
PSRAW mmreg1, mmreg2 0Fh E1h 11-xxx-xxx DirectPath FADD/FMUL 2
PSRAW mmreg, mem64 0Fh E1h mm-xxx-xxx DirectPath FADD/FMUL 4
PSRAW mmreg, imm8 0Fh 71h 11-100-xxx DirectPath FADD/FMUL 2
PSRLD mmreg1, mmreg2 0Fh D2h 11-xxx-xxx DirectPath FADD/FMUL 2
PSRLD mmreg, mem64 0Fh D2h mm-xxx-xxx DirectPath FADD/FMUL 4
PSRLD mmreg, imm8 0Fh 72h 11-010-xxx DirectPath FADD/FMUL 2
PSRLQ mmreg1, mmreg2 0Fh D3h 11-xxx-xxx DirectPath FADD/FMUL 2
PSRLQ mmreg, mem64 0Fh D3h mm-xxx-xxx DirectPath FADD/FMUL 4
PSRLQ mmreg, imm8 0Fh 73h 11-010-xxx DirectPath FADD/FMUL 2
PSRLW mmreg1, mmreg2 0Fh D1h 11-xxx-xxx DirectPath FADD/FMUL 2
PSRLW mmreg, mem64 0Fh D1h mm-xxx-xxx DirectPath FADD/FMUL 4
PSRLW mmreg, imm8 0Fh 71h 11-010-xxx DirectPath FADD/FMUL 2
PSUBB mmreg1, mmreg2 0Fh F8h 11-xxx-xxx DirectPath FADD/FMUL 2
PSUBB mmreg, mem64 0Fh F8h mm-xxx-xxx DirectPath FADD/FMUL 4
PSUBD mmreg1, mmreg2 0Fh FAh 11-xxx-xxx DirectPath FADD/FMUL 2
PSUBD mmreg, mem64 0Fh FAh mm-xxx-xxx DirectPath FADD/FMUL 4
Table 14. MMX™ Technology Instructions (Continued)
Syntax
Encoding
Decode
type
FPU pipe(s) Latency Note
Prefix
byte
First
byte
ModRM byte
Notes:
1. Bits 2, 1, and 0 of the ModRM byte select the integer register.
2. These instructions have an effective latency as shown. However, these instructions generate an internal NOP
with a latency of two cycles but no related dependencies. These internal NOPs can be executed at a rate of
three per cycle and can use any of the three execution resources.