



















Appendix C Instruction Latencies 307
Software Optimization Guide for AMD64 Processors
25112 Rev. 3.06 September 2005
C.4 x87 Floating-Point Instructions
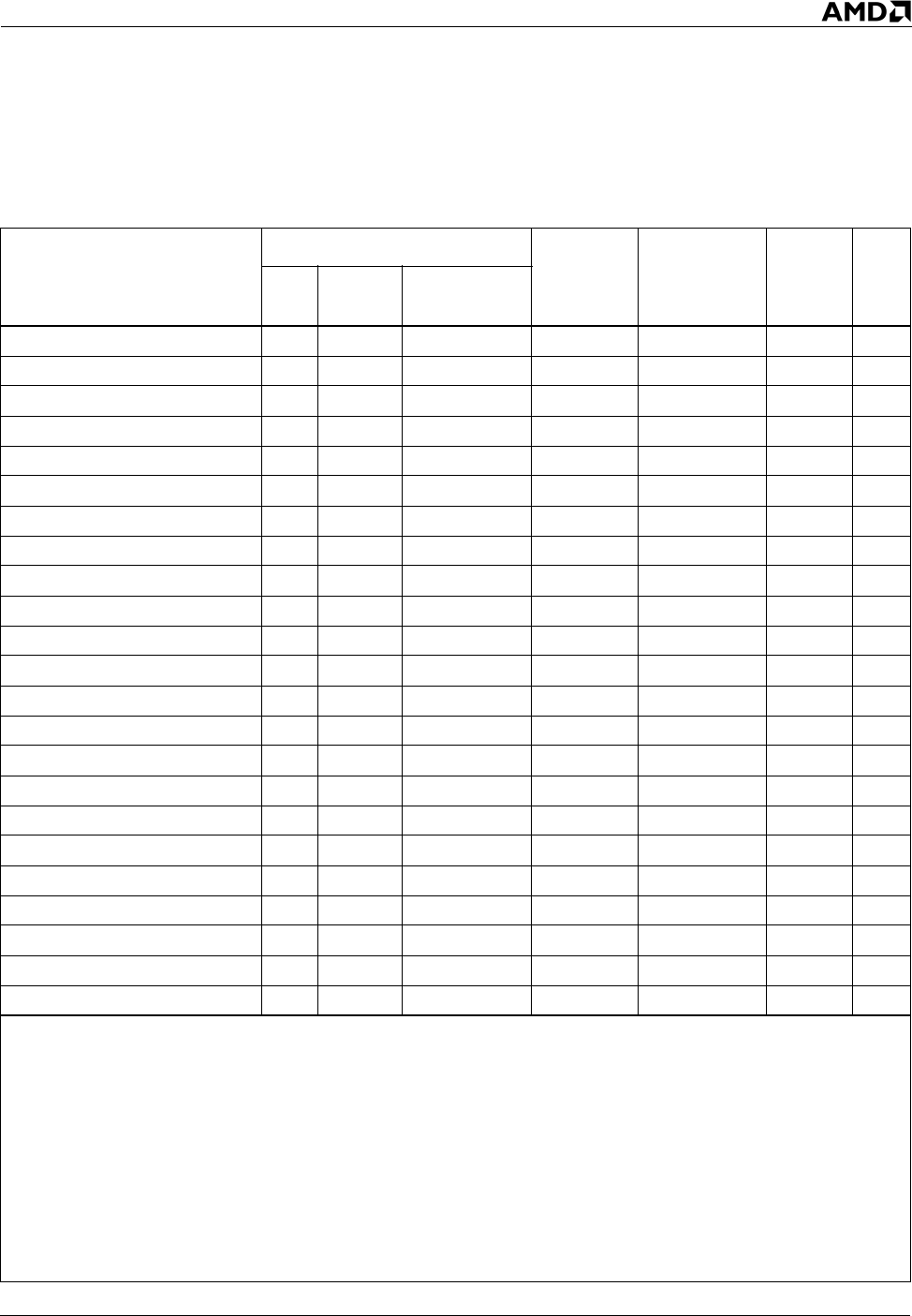
Table 15. x87 Floating-Point Instructions
Syntax
Encoding
Decode
type
FPU
pipe(s)
Latency Note
First
byte
Second
byte
ModRM byte
F2XM1 D9h 11-110-000 VectorPath - 65
FABS D9h 11-100-001 DirectPath FMUL 2
FADD ST, ST(i) D8h 11-000-xxx DirectPath FADD 4 1
FADD [mem32real] D8h mm-000-xxx DirectPath FADD 6
FADD ST(i), ST DCh 11-000-xxx DirectPath FADD 4 1
FADD [mem64real] DCh mm-000-xxx DirectPath FADD 6
FADDP ST(i), ST DEh 11-000-xxx DirectPath FADD 4 1
FBLD [mem80] DFh mm-100-xxx VectorPath - 87
FBSTP [mem80] DFh mm-110-xxx VectorPath - 172
FCHS D9h 11-100-000 DirectPath FMUL 2
FCLEX DBh E2h 11-100-010 VectorPath - ~
FCMOVB ST(0), ST(i) DAh 11-000-xxx VectorPath - 15 5
FCMOVBE ST(0), ST(i) DAh 11-010-xxx VectorPath - 15 5
FCMOVE ST(0), ST(i) DAh 11-001-xxx VectorPath - 15 5
FCMOVNB ST(0), ST(i) DBh 11-000-xxx VectorPath - 15 5
FCMOVNBE ST(0), ST(i) DBh 11-010-xxx VectorPath - 15 5
FCMOVNE ST(0), ST(i) DBh 11-001-xxx VectorPath - 15 5
FCMOVNU ST(0), ST(i) DBh 11-011-xxx VectorPath - 15 5
FCMOVU ST(0), ST(i) DAh 11-011-xxx VectorPath - 15 5
FCOM ST(i) D8h 11-010-xxx DirectPath FADD 2 1
FCOM [mem32real] D8h mm-010-xxx DirectPath FADD 4
FCOM [mem64real] DCh mm-010-xxx DirectPath FADD 4
FCOMI ST, ST(i) DBh 11-110-xxx VectorPath FADD 3 3
Notes:
1. The last three bits of the ModRM byte select the stack entry ST(i).
2. These instructions have an effective latency as shown. However, these instructions generate an internal NOP
with a latency of two cycles but no related dependencies. These internal NOPs can be executed at a rate of
three per cycle and can use any of the three execution resources.
3. This is a VectorPath decoded operation that uses one execution pipe (one ROP).
4. There is additional latency associated with this instruction. “e” represents the difference between the exponents
of the divisor and the dividend. If “s” is the number of normalization shifts performed on the result, then
n = (s+1)/2 where (0 <= n <= 32).
5. The latency provided for this operation is the best-case latency.
6. The three latency numbers represent the latency values for precision control settings of single precision, double
precision, and extended precision, respectively.