


















AMD Geode™ LX Processors Data Book 673
Instruction Set
33234H
1) These instructions must wait for the FPU pipeline to flush. Cycle count depends on what instructions are in the pipe-
line.
2) The AMD Geode LX processor performs PFRCP and PFRSQRT to 24-bit accuracy in one cycle, so these instructions
are unnecessary. They are treated as a move.
3) Non-standard AMD 3DNow! instruction. See Section 8.4.1 on page 674 for details.
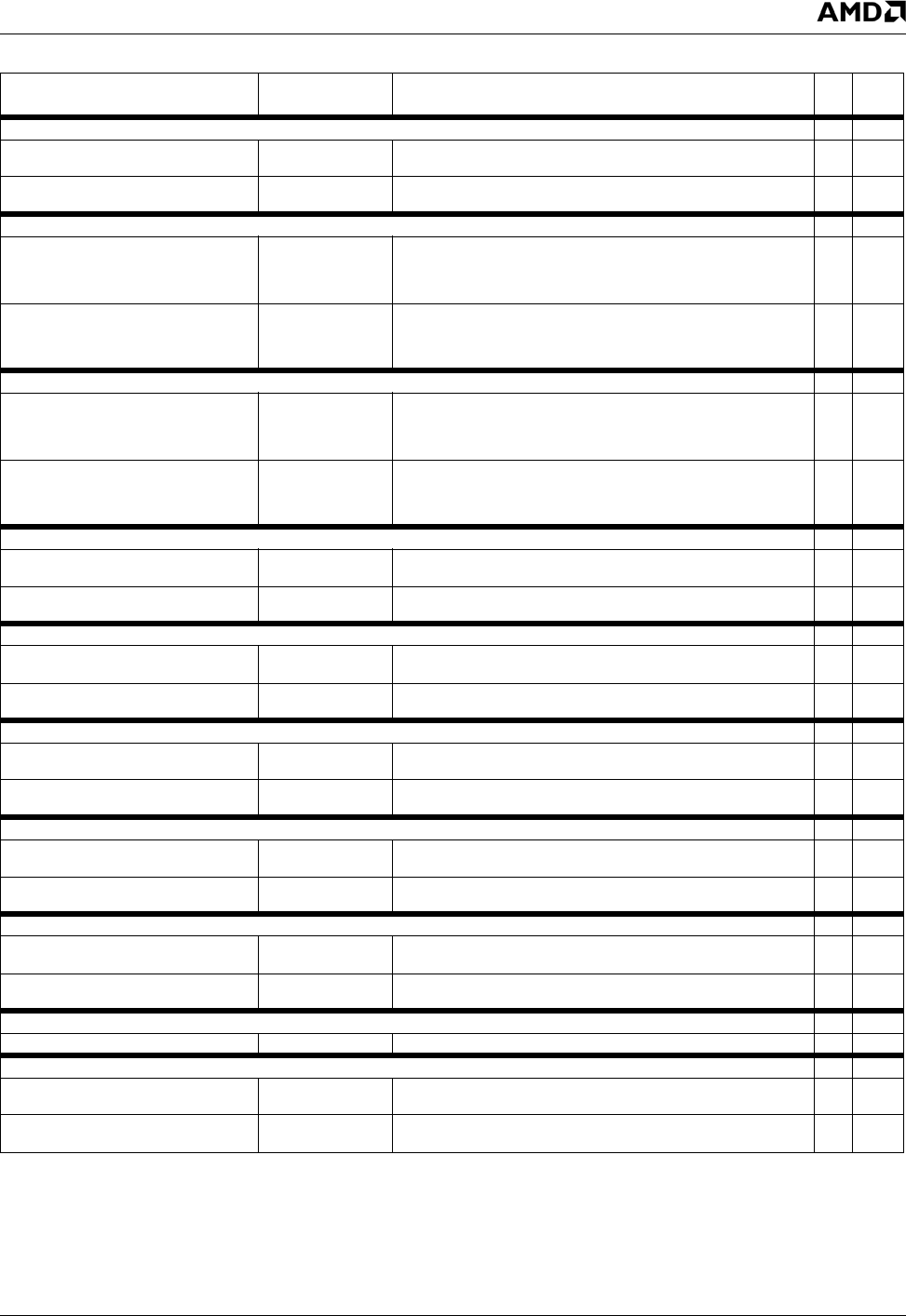
PFSRQIT1 Packed Floating-Point Reciprocal Square Root, First Iteration Step 11, 2
MMX Register1 with MMX Register 2 0F0F [11 mm1
mm2] A7
MMX reg 1 [dword] <--- move --- MMX reg 2 [dword]
MMX Register with Memory64 0F0F [mod mm r/m]
A7
MMX reg [dword] <--- move --- Memory64 [dword]
PFRSQRT Floating-Point Reciprocal Square Root 2
MMX Register 1 by MMX Register 2 0F0F [11 mm1
mm2] 97
MMX reg.1 [low dword] <--- reciprocal --- square root --- MMX reg 2
[low dword]
MMX reg 2 [high dword] <--- reciprocal --- square root --- MMX reg 2
[low dword]
MMX Register by Memory64 0F0F [mod mm r/m]
97
MMX reg [low dword] <--- reciprocal --- square root --- Memory64 [low
dword]
MMX reg [high word] <--- reciprocal --- square root --- Memory64 [low
dword]
PFRSQRTV Floating-Point Reciprocal Square Root Vector 23
MMX Register1 with MMX Register2 0F0F [11 mm1
mm2] 87
MMX reg 1 [low dword] <--- sat --- reciprocal --- square root --- MMX
reg 2 [low dword]
MMX reg 1 [high word] <--- sat --- reciprocal --- square root --- MMX reg
2 [high dword]
MMX Register with Memory64 0F0F [mod mm r/m]
87
MMX reg [low dword] <---sat --- reciprocal --- square root --- Memory64
[low dword]
MMX reg [high dword] <--- sat --- reciprocal --- square root ---
Memory64 [high dword]
PFSUB Packed Floating- Point Subtraction 2
MMX Register1 with MMX Register2 0F0F [11 mm1
mm2] 9A
MMX reg 1 [dword] <--- (MMX reg1 [dword] - MMX reg 2 [dword])
MMX Register with MMX Memory64 0F0F [mod mm r/m
9A
MMX reg [dword] <--- (MMX reg [dword] - Memory64 [dword])
PFSUBR Packed Floating-Point Reverse Subtraction 2
MMX Register1 with MMX Register2 0F0F [11mm1 mm2]
AA
MMX reg 1 [dword] <---(MMX reg 2 [dword] - MMX reg [dword])
MMX Register with Memory64 0F0F [mod mm r/m]
AA
MMX REG [dword] <--- (Memory64 [dword] - MMX reg [dword])
PI2FD Packed 32-Bit Integer to Floating-Point Conversion 2
MMX Register1 by MMX Regester2 0F0F [11 mm1
mm2] 0D
MMX reg 1 [dword] <--- trun --- float --- MMX reg 2 [dword]
MMX Register by Memory64 0F0F [mod mm r/m]
0D
MMX reg [dword] <--- trun --- float --- Memory64 [dword]
PIF2W Packed Integer Word to Floating-Point Conversion 2
MMX Register1 by MMX Register2 0F0F [11 mm1
mm2] 0C
MMX reg 1 [low dword] <--- float --- MMX reg 2 [low word (low dword)]
MMX reg 1 [high dword] <--- float --- MMX reg 2 [low word (high dword)]
MMX Register by Memory64 0F0F [mod mm r/m]
0C
MMX reg [low dword] <--- float --- Memory64 [low word (low dword)]
MMX reg [high dword] <--- float --- Memory64 [low dword (high dword)]
PMULHRW Multiply Signed Packed 16-bit Value with Rounding and Store the High 16 bits 2
MMX Register1 with MMX Register2 0F0F [11 mm1 mm2
B7
MMX reg 1 [word] <--- (MMX reg 1 [word] * MMX reg 2 [word]) + 8000h
MMX Register with Memory64 0F0F [mod mm r/m
B7
MMX reg [word] <--- (MMX reg [word] * Memory64 [word]) + 8000h
PREFETCH/PREFETCHW Prefetch Cache Line into L1 Data Cache (Dcache)
Memory 8 0F0D
PSWAPD Packed Swap Doubleword 1
MMX Register1 by MMX Register2 0F0F [11 mm1
mm2] BB
MMX reg 1 [low dword] <--- MMX reg 2 [high dword]
MMX reg 1 [high dword] <--- MMX reg 2 [low dword]
MMX Register by Memory64 0F0F [mod mm r/m]
BB
MMX reg [low dword] <--- Memory64 [high dword]
MMX reg [high dword] <--- Memory64 [low dword]
Table 8-30. AMD 3DNow!™ Technology Instruction Set (Continued)
AMD 3DNow!™ Instructions Opcode/imm8 Operation
Clk
Cnt
Notes