



















Chapter 23. Global Mirror options and configuration 283
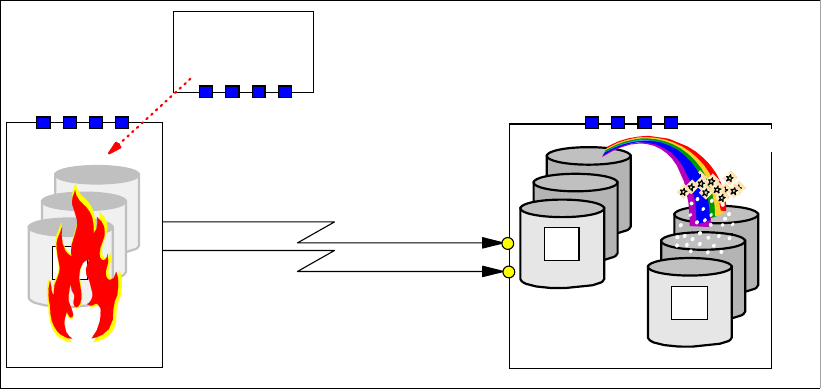
Figure 23-10 Primary site fails
The goal is to swap to the remote site and restart the applications. This requires, first, to make
the set of consistent volumes at the remote site available for the application, before the
application can be restarted at the remote site.
Then, once the local site is back and operational again, we have to return to the local site.
Before returning to the local site, we have to apply, to the primary volumes, the changes that
the application made to the secondary data while it was running at the remote site. After this,
we should be doing a quick swap back to the local site and restart the application.
When the local storage disk subsystem fails, Global Mirror can no longer form Consistency
Groups. Depending on the state of the local storage disk subsystem, you may be able to
terminate the Global Mirror session. Usually this is not possible because the storage disk
subsystem may not respond any more. Host application I/O may have failed and the
application ended. This usually goes along with messages or SNMP alerts that indicate the
problem. With automation in place, as for example Geographically Dispersed Parallel
Sysplex™ (GDPS) or eRCMF, these alert messages trigger the initial recovery actions.
If the formation of a Consistency Group was in progress, then, most probably, not all
FlashCopy relationships between the B and C volumes at the remote site will have reached
the corresponding point-in-time. Some FlashCopy pairs may have completed the FlashCopy
phase to form a new Consistency Group, and committed the changes already. Others may
not have completed yet, and are in the middle of forming their consistent copy, and remain in
a revertible state. And there is no Master any longer to control and coordinate what may still
be going on. All of this forces a closer look at the volumes at the remote site before we can
continue to work with them. There will be more discussion of this in the following sections.
First, however, we just bring the B volumes into a usable state using the failover command.
23.7.3 Failover B volumes
Because the primary storage disk subsystem may no longer be usable, the recovery actions
and processing now occur at the remote site, using a host connected to the remote disk
subsystems. For this, you may use either TSO commands or ICKDSF.
When there is no host connected to the remote disk subsystem, you may still carry on the
necessary management activities through the Web-based GUI interface or using the DS CLI
FlashCopy
Global Copy
Primary
Primary
A
Primary
Primary
A
Tertiary
C
Primary
Primary
A
Primary
Primary
A
Secondary
B
Host
Remote site
Primary
Primary
A
Primary
Primary
A
Primary
A
PENDING
PENDING
Local site