


















338 IBM System Storage DS6000 Series: Copy Services with IBM System z
The following example addresses the impact of the coordination time when Consistency
Group formation starts, and whether this impact has the potential to be significant or not.
Assume a total aggregated number of 5000 write I/Os over two primary storage disk
subsystems, with 2500 write I/Os per second to each storage disk subsystem. Each write I/O
takes 0.5 ms. You specified 3 ms maximum to coordinate between the master storage disk
subsystem and its subordinate storage disk subsystem. Assume further that a Consistency
Group is created every 3 seconds, which is a goal with the Consistency Group interval time of
zero. To summarize:
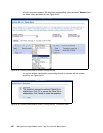
5000 write I/Os
0.5 ms response time for each write I/O
Maximum coordination time is 3 ms
Every 3 seconds a Consistency Group is created
This is 5 I/Os for every millisecond or 15 I/Os within 3 ms. So each of these 15 write I/Os
experience a 3 ms delay. This happens every 3 seconds. Then we observe an average
response time delay of approximately:
(15 IOs * 0.003 sec) / 3*5000 IO/sec) = 0.000003 sec or 0.003 ms.
The response time increases on average from 0.5 ms to 0.503 ms. RMF is currently not
capable of even showing such a small difference.
25.3 Consistency Group transmission
After the Consistency Group is established at the primary storage disk subsystems with the
corresponding bitmaps within the coordination time window, all remaining data that is still in
the out-of-sync bitmap is sent to the secondary storage disk subsystem with Global Copy.
This drain period can also be limited to replicate all remaining data from the primary to the
secondary storage disk subsystem in a time limit set by the
maximum drain time. The default
is 30 seconds and is considered to be too small in a potentially write-intensive workload. A
number in the range of 300 seconds to 600 seconds can be considered.
This replication process usually does not impact the application write I/O. There is a very low
chance that the very same track in a Consistency Group might be updated before this track is
replicated to the secondary site, while in this drain time period. When this unlikely event
happens, the track is immediately replicated to the secondary storage disk subsystem, before
the application write I/O modifies the original track. The application write I/O is going to
experience a response time similar to that experienced if the I/O had been written to a Metro
Mirror primary volume.
25.4 Remote storage disk subsystem configuration
There will be I/O skews and hot spots in the storage disk subsystems. This is true for the local
and remote storage disk subsystems. For the local storage disk subsystems, you can
consider a horizontal pooling approach, and spread each volume type across all ranks.
Volume types are in this context, for example, DB2® database volumes, logging volumes,
batch volumes, temporary volumes, and so forth. Your goal might be to have the same
number of each volume type within each rank.
Through a one-to-one mapping from the local to the remote storage disk subsystem, you
achieve the same configuration at the remote site for the B volumes and the C volumes.