



















User’s Manual
IBM PowerPC 750GX and 750GL RISC Microprocessor
Instruction Timing
Page 226 of 377
gx_06.fm.(1.2)
March 27, 2006
Performance features such as branch folding, BTIC, dynamic branch prediction (implemented in the BHT),
2-level branch prediction, and the implementation of nonblocking caches minimize the penalties associated
with flow-control operations on the 750GX. The timing for branch instruction execution is determined by many
factors including:
• Whether the branch is taken
• Whether instructions in the target stream, typically the first two instructions in the target stream, are in the
branch target instruction cache (BTIC)
• Whether the target instruction stream is in the L1 cache
• Whether the branch is predicted
• Whether the prediction is correct
6.4.1.1 Branch Folding
When a branch instruction is encountered by the fetcher, the BPU immediately begins to decode it and tries
to resolve it. Branch folding is the removal of branches from the instruction stream. This is independent of
whether the branch is taken or not taken. However, if the branch instruction updates either the LR or CTR it
cannot be removed and must be allocated a position in the completion queue. If a branch cannot be resolved
immediately, it is predicted and instruction fetching resumes along the predicted path. Those instructions are
conditionally fed into the instruction queue. Later, if the prediction is finally correctly resolved, the fetched
instructions are validated and allowed to complete and be retired. If the prediction is resolved incorrectly, then
the instructions fetched are invalidated, and instruction fetching resumes along the other path of the branch.
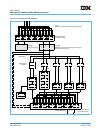
Figure 6-7 on page 227 shows branch folding. Here a b instruction is encountered in a series of add instruc-
tions. The branch is resolved as taken. What happens on the next clock cycle depends on whether the target
instruction stream is in the BTIC, the instruction L1 cache, or if it must be fetched from the L2 cache or from
system memory.
Figure 6-7 shows cases where there is a BTIC hit, and where there is a BTIC miss (and instruction-cache hit).
If there is a BTIC hit on the next clock cycle, the bx instruction is replaced by the target instruction, and1,
which was found in the BTIC. The second and instruction is also fetched from the BTIC. On the next clock
cycle, the next four and instructions from the target stream are fetched from the instruction cache.
If the target instruction is not in the BTIC, there is an idle cycle while the fetcher attempts to fetch the first four
instructions from the instruction cache (on the next clock cycle). In the example in Figure 6-7, the first four
target instruction are fetched on the next clock.
If the target instruction misses in the BTIC or L1 caches, an L2 cache or memory access is required. The
latency of this access is dependent on several factors, such as processor/bus clock ratios. In most cases,
new instructions arrive in the IQ before the execution units become idle.