



















328
Example 22
The Akaike weight has been interpreted (Akaike, 1978; Bozdogan, 1987; Burnham and
Anderson, 1998) as the likelihood of the model given the data. With this interpretation,
the estimated K-L best model (Model 7) is only about 2.4 times more likely (0.494 /
0.205 = 2.41) than Model 6. Bozdogan (1987) points out that, if it is possible to assign
prior probabilities to the candidate models, the prior probabilities can be used together
with the Akaike weights (interpreted as model likelihoods) to obtain posterior
probabilities. With equal prior probabilities, the Akaike weights are themselves
posterior probabilities, so that one can say that Model 7 is the K-L best model with
probability 0.494, Model 6 is the K-L best model with probability 0.205, and so on. The
four most probable models are Models 7, 6, 8, and 1. After adding their probabilities
(0.494 + 0.205 + 0.192 + 0.073 = 0.96), one can say that there is a 96% chance that the
K-L best model is among those four. (Burnham and Anderson, 1998, pp. 127-129). The
p subscript on BCC
p
serves as a reminder that BCC
p
can be interpreted as a probability
under some circumstances.
Using BIC to Compare Models
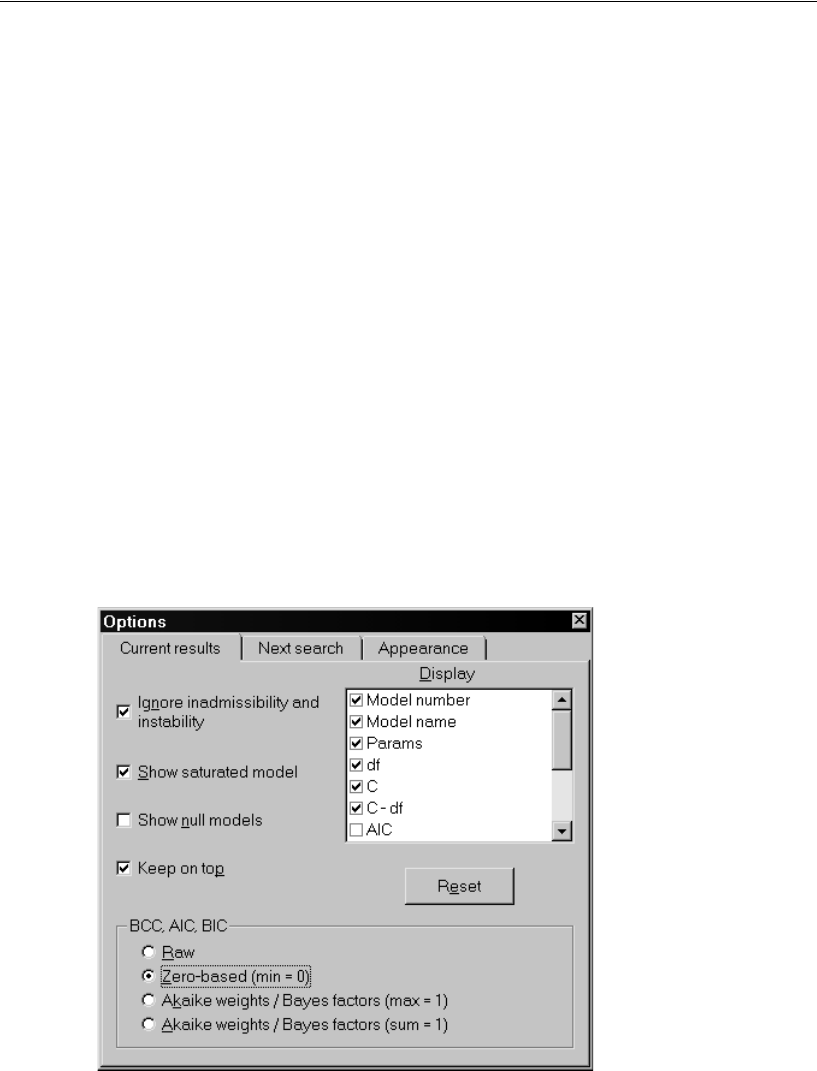
E On the Current results tab of the Options dialog box, select Zero-based (min = 0) in the
BCC, AIC, BIC group.