



















C-2 PPC405 Core User’s Manual
Because this method adds interrupt context switching time to the execution time of library routines
that would have been called directly by the preferred method, it is not preferred. However, this method
supports code that contains PowerPC floating-point instructions.
C.1.4 Cache Usage
Code and data can be organized, based on the size and structure of the instruction and data cache
arrays, to minimize cache misses.
In the cache arrays, any two addresses in which A
m
:26
(the index) are the same, but which differ in
A
0:
m
-1
(the tag), are called congruent. (This describes a two-way set-associative cache.) A
27:31
define
the 32 bytes in a cache line, the smallest object that can be brought into the cache. Only two
congruent lines can be in the cache simultaneously; accessing a third congruent line causes the
removal from the cache of one of the two lines previously there
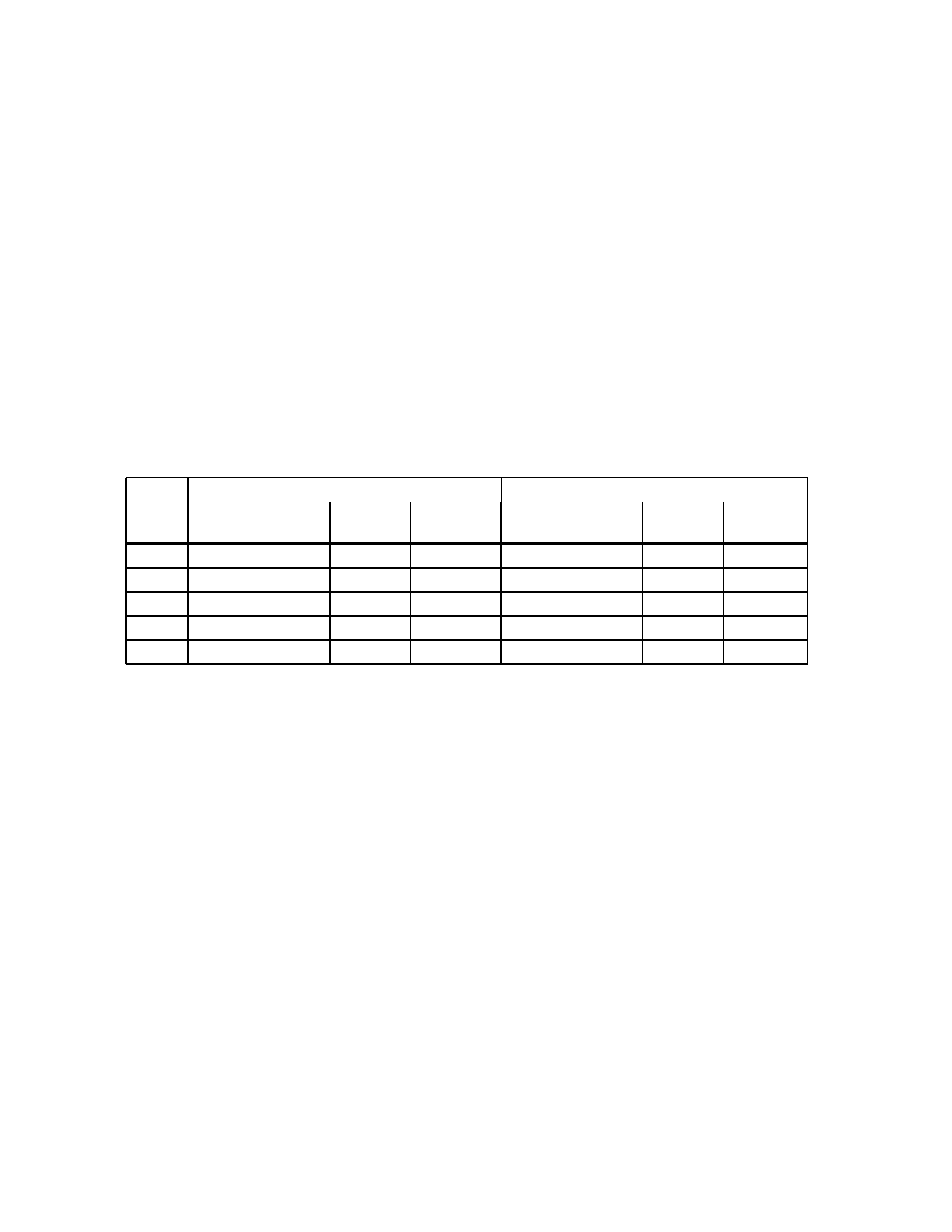
Table C-1 illustrates the value of
m
and the index size for the various cache array sizes.
Moving new code and data into the cache arrays occurs at the speed of external memory. Much faster
execution is possible when all code and data is available in the cache. Organizing code to uniformly
use A
m
:26
minimizes the use of congruent addresses.
C.1.5 CR Dependencies
For CR-setting arithmetic, compare, CR-logical, and logical instructions, and the CR-setting mcrf,
mcrxr, and mtcrf instructions, put two instructions between the CR-setting instruction and a Branch
instruction that uses a bit in the CR field set by the CR-setting instruction.
C.1.6 Branch Prediction
Use the Y-bit in branch instructions to force proper branch prediction when there is a more likely
prediction than the standard prediction. See “Branch Prediction” on page 2-26 for a more information
about branch prediction.
C.1.7 Alignment
For speed, align all accesses on the appropriate operand-size boundary. For example, load/store
word operands should be word-aligned, and so on. Hardware does not trap unaligned accesses;
instead, two accesses are performed for a load or store of an unaligned operand that crosses a word
boundary. Unaligned accesses that do not cross word boundaries are performed in one access.
Table C-1. Cache Sizes, Tag Fields, and Lines
Instruction Cache Array Data Cache Array
Array
Size
m
(Tag Field Bits)
n
(Lines) Index Bits
m
(Tag Field Bits)
n
(Lines)
Index Bits
0KB — — — — — —
4KB 22 (0:21) 64 21:26 20 (0:19) 64 21:26
8KB 22 (0:21) 128 20:26 20 (0:19) 128 20:26
16KB 22 (0:21) 256 19:26 20 (0:19) 256 19:26
32KB 22 (0:21) 512 18:26 20 (0:19) 512 18:26